


论文题目:Assisted Excitation of Activations: A Learning Technique to Improve Object Detectors(CVPR2019)
论文下载: 点击下载
摘要:
在训练过程中,加入定位信息。可是提升yolov2 map 3.8个点, yolov3 map 2.2个点。这个方法适用于大多数single-stage 目标检测器。只改变了训练过程,推断过程没有任何改变。
Introduction:
yolo难以解决得两个痛点:
a. difficulty in localization
原因:因为yolo同时做分类和定位,最后一层卷积层,更多语义信息,对分类有益。但是spatially course for localization.
b. 训练时,前景与背景类别不平衡
原因:不同于two-stage 检测器,没有预先减少候选框搜索空间到一个受限制的数目。大多数是简单的负样本。
Related Work:
加入辅助信息到CNN,主要分类两类:
1.同时做检测和分割,提升两个任务的表现。
2.只加入segmentation features来提高检测的精度。
本文提出的方法,在训练检测器时加入weak segmentation ground-truth(即bounding box,从而避免单独引入分割标注,更加简单),并没有增加额外的损失函数。
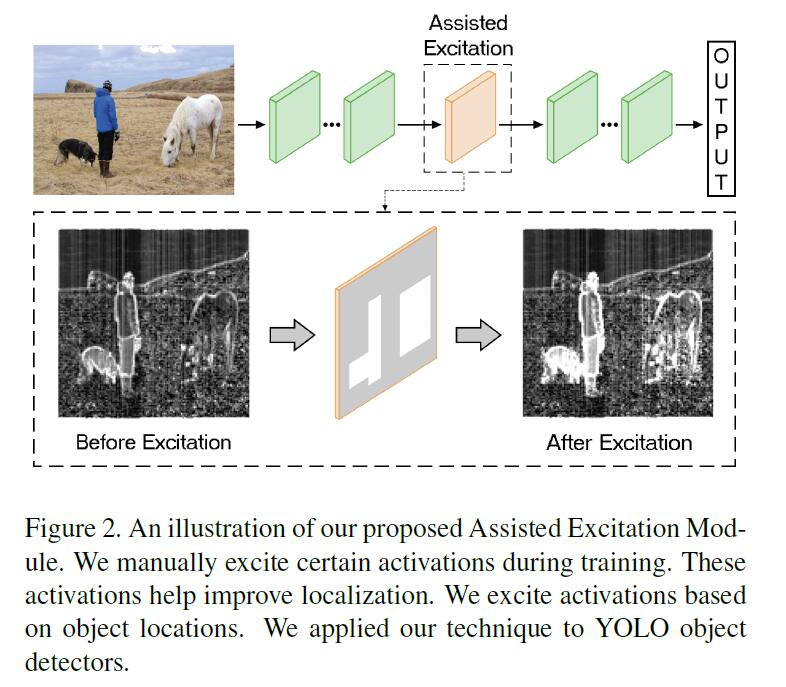
如上图所示,只在训练时增加了一个Assisted Excitation层。
具体过程:
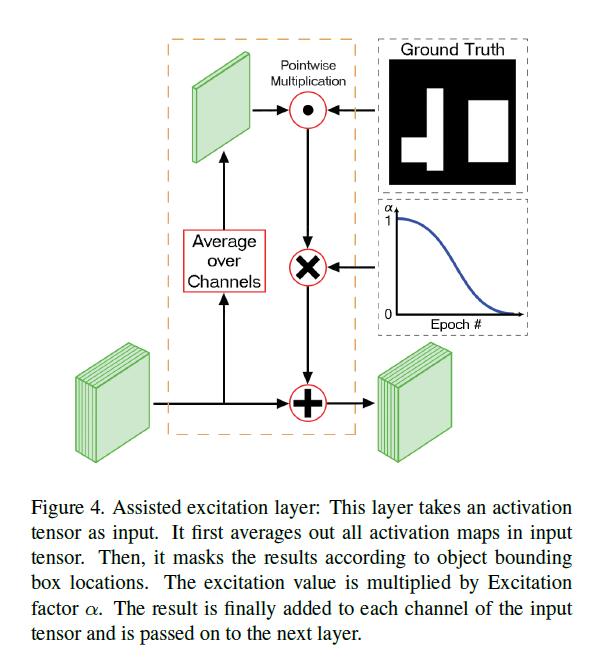
最终期望的生成特征如下,其中alpha是关于时间的函数用于控制训练中的强度衰减,l+1代表第l+1层,式中c为通道数,e是增强特征:
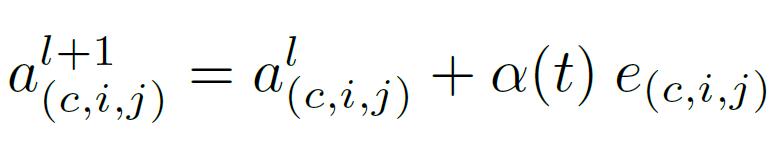
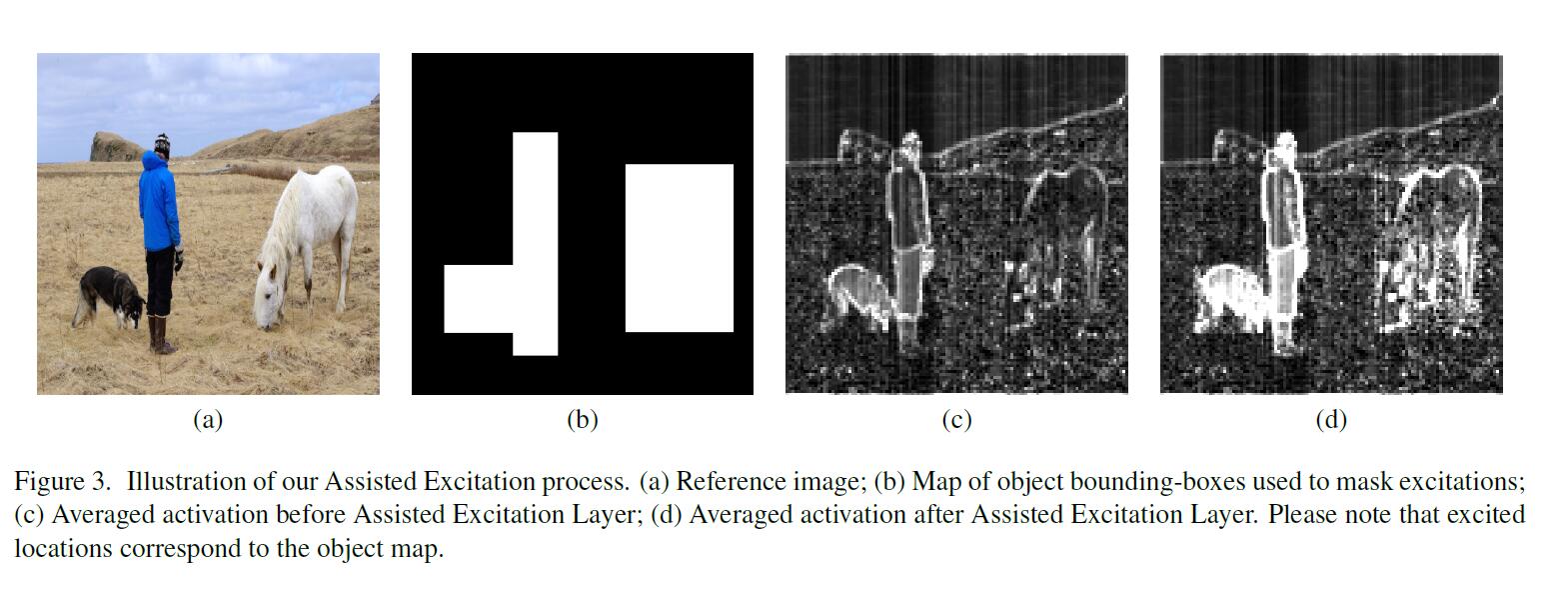
bbox内的像素位置为1,生成一个0-1mask。可见只在bbox内的区域做增强:
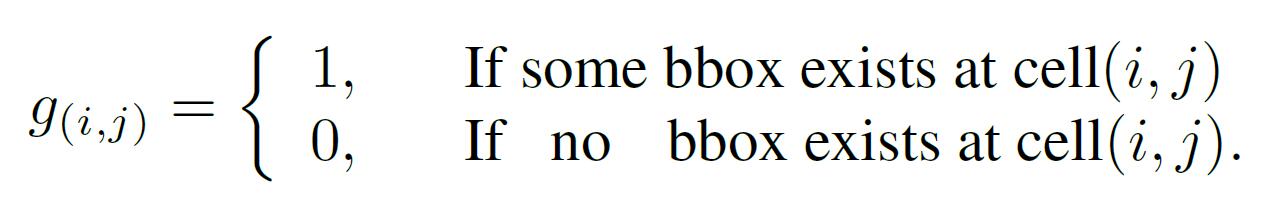
增强是按照通道去平均等量加上去的(作者的实验证明该效果最好):
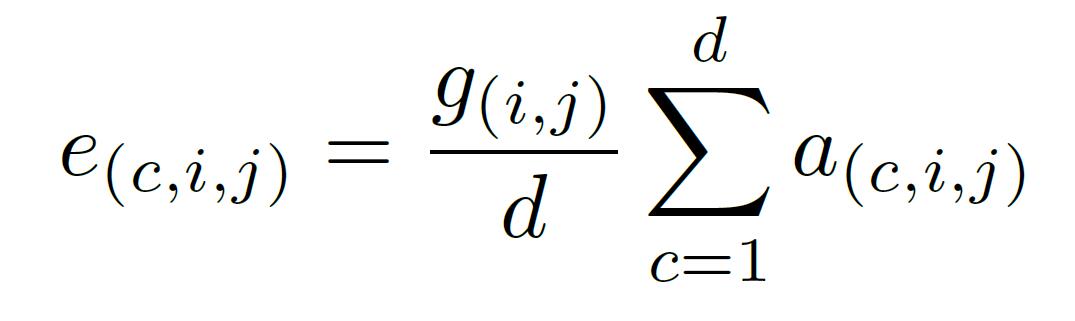
实验结果:
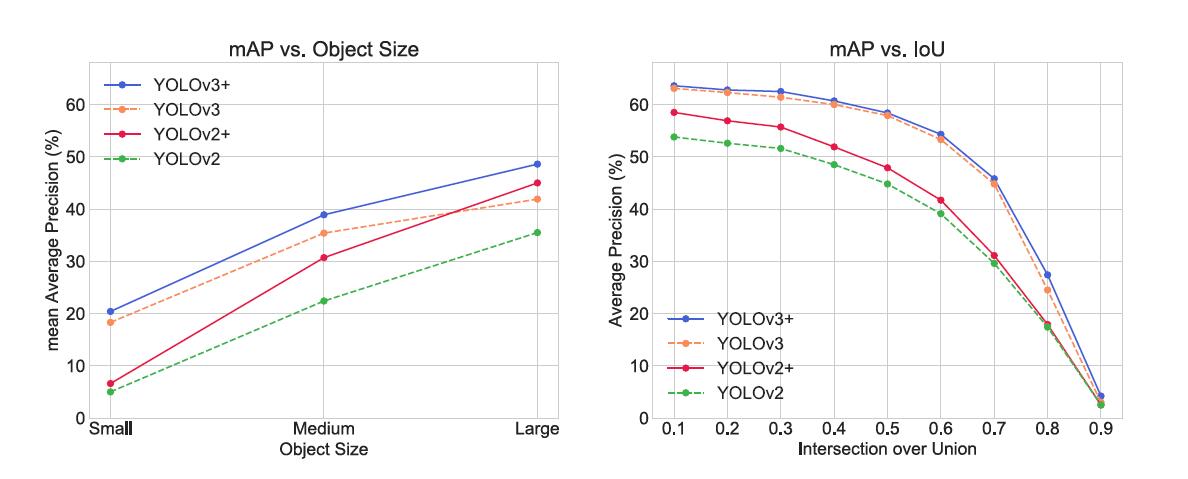
从上左边的图可以看到,AE强化过的网络有全面的提升,其中在大尺度上的提升更加明显,推测原因是:大物体上加了分割强化后能够获得更强的辨认度,小物体由于本身尺度不大所以增加后也不明显。结果而言印证了这种强化的有效性,但是也完全地陷入了小目标检测的弊端了--像素内容少而被忽视。
右图的信息不太好辨认。先看yolov2的曲线来说,低iou阈值能够得到更高的改进的精度,说明其召回更好了,但是精度一高就趋于重合,改进失效,说明这种增强提高了低质量bbox的精度。再看yolov3,全IoU都有少量的提高,但是不特别大且没有明显的趋势,说明其采用的多尺度预测能一定程度地解决问题,并在其基础上能对全部精度都有增益。
评论区