


对象识别和定位,可以看成两个任务:找到图片中某个存在对象的区域,然后识别出该区域中具体是哪个对象。
对象识别这件事(一张图片仅包含一个对象,且基本占据图片的整个范围),最近几年基于CNN卷积神经网络的各种方法已经能达到不错的效果了。所以主要需要解决的问题是,对象在哪里。
最简单的想法,就是遍历图片中所有可能的位置,地毯式搜索不同大小,不同宽高比,不同位置的每个区域,逐一检测其中是否存在某个对象,挑选其中概率最大的结果作为输出。显然这种方法效率太低。
- RCNN提出候选区(Region Proposals)的方法,先从图片中搜索出一些可能存在对象的候选区(Selective Search),然后对每个候选区进行对象识别。大幅提升了对象识别和定位的效率。总体来说,RCNN系列依然是两阶段处理模式:先提出候选区,再识别候选区中的对象。
- yolov1 yolov1详解(非常详细,推荐)
补充:
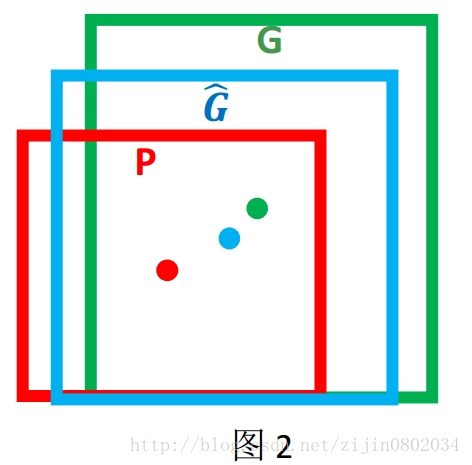
边框回归:对于窗口一般使用四维向量(x,y,w,h)来表示, 分别表示窗口的中心点坐标和宽高。 对于图 2, 红色的框 P 代表原始的Proposal, 绿色的框 G 代表目标的 Ground Truth, 我们的目标是寻找一种关系使得输入原始的窗口 P 经过映射得到一个跟真实窗口 G 更接近的回归窗口G^。
YOLOV1的bounding box并不是Faster RCNN的Anchor
Faster RCNN等一些算法采用每个grid中手工设置n个Anchor(先验框,预先设置好位置的bounding box)的设计,每个Anchor有不同的大小和宽高比。YOLO的bounding box看起来很像一个grid中2个Anchor,但它们不是。YOLO并没有预先设置2个bounding box的大小和形状,也没有对每个bounding box分别输出一个对象的预测。它的意思仅仅是对一个对象预测出2个bounding box,选择预测得相对比较准的那个。
- Yolov2 yolov2
改变:
batch normalization,
采用了anchor,借鉴Faster RCNN的做法,YOLO2也尝试采用先验框(anchor)。在每个grid预先设定一组不同大小和宽高比的边框,来覆盖整个图像的不同位置和多种尺度,这些先验框作为预定义的候选区在神经网络中将检测其中是否存在对象,以及微调边框的位置。
评论区